

 English
Englishpython使用深度神经网络实现识别暹罗与英短
先来上两张图看看那种猫是暹罗?那种猫是英短?
第一张暹罗

第二张英短

你以后是不是可以识别了暹罗和英短了?大概能,好像又不能。这是因为素材太少了,我们看这两张图能分别提取出来短特征太少了。那如果我们暹罗短放100张图,英短放100张图给大家参考,再给一张暹罗或者英短短照片是不是就能识别出来是那种猫了,即使不能完全认出来,是不是也有90%可能是可以猜猜对。那么如果提供500张暹罗500张英短短图片呢,是不是猜对的概率可以更高?
我们是怎么识别暹罗和英短的呢?当然是先归纳两种猫的特征如面部颜色分布、眼睛的颜色等等,当再有一张要识别短图片时,我们就看看面部颜色分布、眼睛颜色是不是可暹罗的特征一致。
同样把识别暹罗和英短的方法教给计算机后,是不是计算机也可以识别这两种猫?
那么计算机是怎么识别图像的呢?先来看一下计算机是怎么存储图像的。
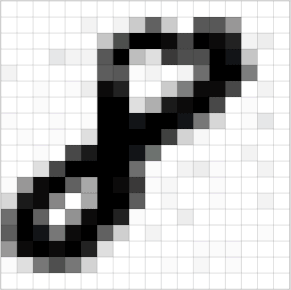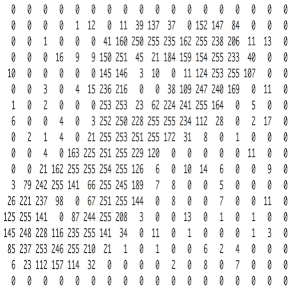
图像在计算机里是一堆按顺序排列的数字,1到255,这是一个只有黑白色的图,但是颜色千变万化离不开三原色——红绿蓝。
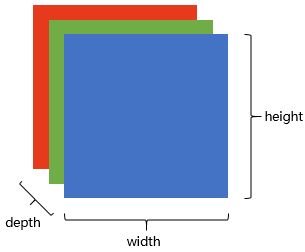
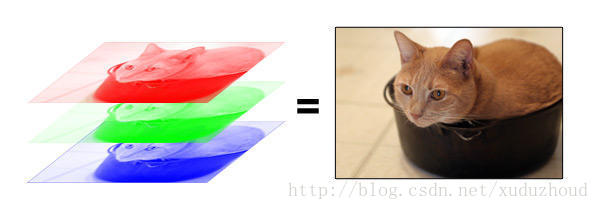
这样,一张图片在计算机里就是一个长方体!depth为3的长方体。每一层都是1到255的数字。
让计算机识别图片,就要先让计算机了解它要识别短图片有那些特征。提取图片中的特征就是识别图片要做的主要工作。
下面就该主角出场了,卷及神经网络(Convolutional Neural Network, CNN).
最简单的卷积神经网络就长下面的样子。
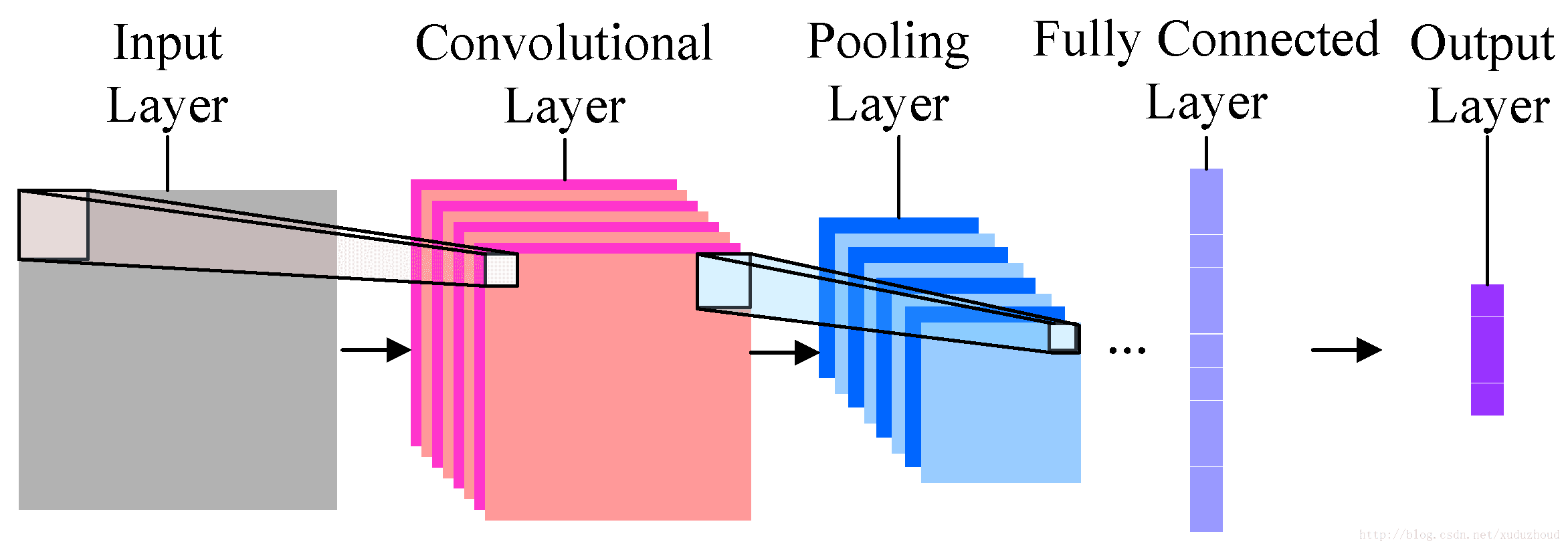
分为输入、卷积层、池化层(采样层)、全连接和输出。每一层都将最重要的识别信息进行压缩,并传导至下一层。
卷积层:帮助提取特征,越深(层数多)的卷积神经网络会提取越具体的特征,越浅的网络提取越浅显的特征。
池化层:减少图片的分辨率,减少特征映射。
全连接:扁平化图片特征,将图片当成数组,并将像素值当作预测图像中数值的特征。
•卷积层
卷积层从图片中提取特征,图片在计算机中就上按我们上面说的格式存储的(长方体),先取一层提取特征,怎么提取?使用卷积核(权值)。做如下短操作:
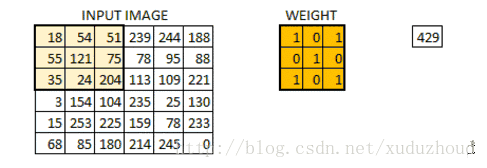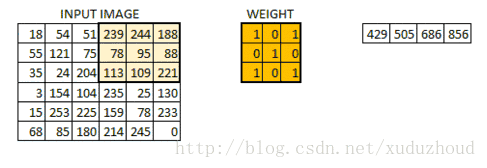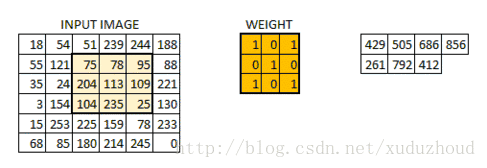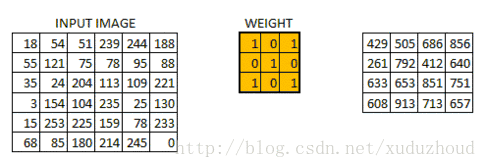
观察左右两个矩阵,矩阵大小从6×6 变成了 4×4,但数字的大小分布好像还是一致的。看下真实图片:

图片好像变模糊了,但这两个图片大小没变是怎么回事呢?其实是用了如下的方式:same padding
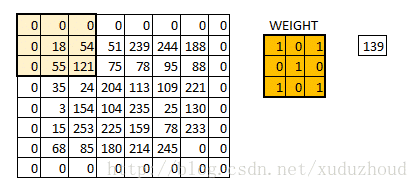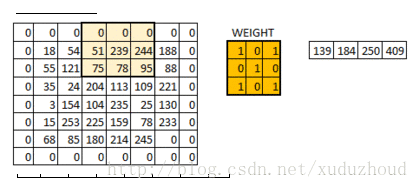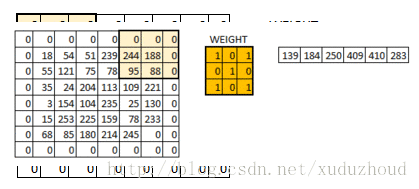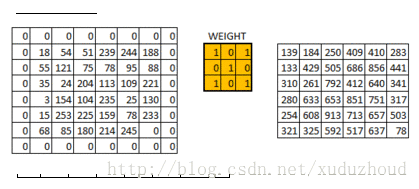
在6×6的矩阵周围加了一圈0,再做卷积的时候得到的还是一个6×6的矩阵,为什么加一圈0这个和卷积核大小、步长和边界有关。自己算吧。
上面是在一个6×6的矩阵上使用3X3的矩阵做的演示。在真实的图片上做卷积是什么样的呢?如下图:

对一个32x32x3的图使用10个5x5x3的filter做卷积得到一个28x28x10的激活图(激活图是卷积层的输出).
•池化层
减少图片的分辨率,减少特征映射。怎么减少的呢?
池化在每一个纵深维度上独自完成,因此图像的纵深保持不变。池化层的最常见形式是最大池化。
可以看到图像明显的变小了。如图:
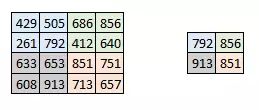
在激活图的每一层的二维矩阵上按2×2提取最大值得到新的图。真实效果如下:
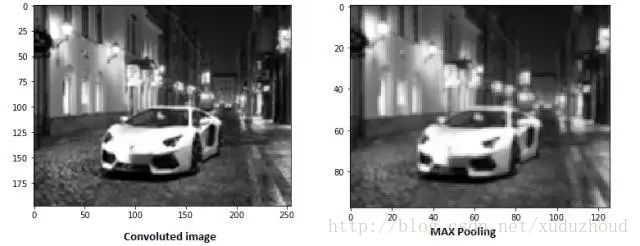
随着卷积层和池化层的增加,对应滤波器检测的特征就更加复杂。随着累积,就可以检测越来越复杂的特征。这里还有一个卷积核优化的问题,多次训练优化卷积核。
下面使用apple的卷积神经网络框架TuriCreate实现区分暹罗和英短。(先说一下我是在win10下装的熬夜把电脑重装了不下3次,系统要有wls,不要用企业版,mac系统和ubuntu系统下安装turicreae比较方便)
首先准备训练用图片暹罗50张,英短50长。测试用图片10张。
上代码:(开发工具anaconda,python 2.7)
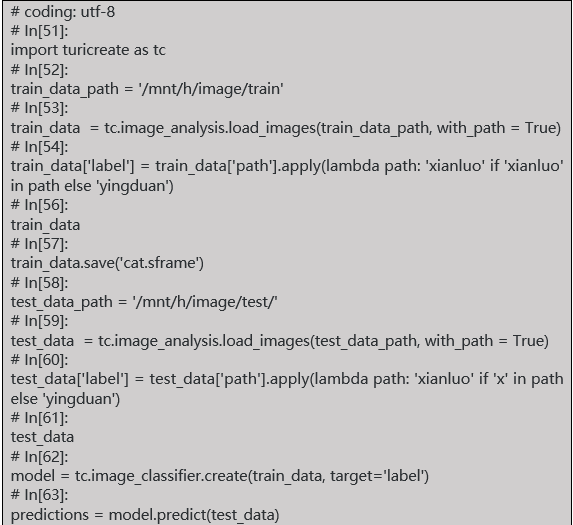

数据放到了h盘image目录下,我是在win10下装的ubuntu,所以h盘挂在mnt/下。
test的文件:(x指暹罗,y指英短,这样命名是为了代码里给测试图片区分猫咪类型)

test_data[‘label’] = test_data[‘path’].apply(lambda path: ‘xianluo’ if ‘x’ in path else ‘yingduan’)
第一次结果如下:
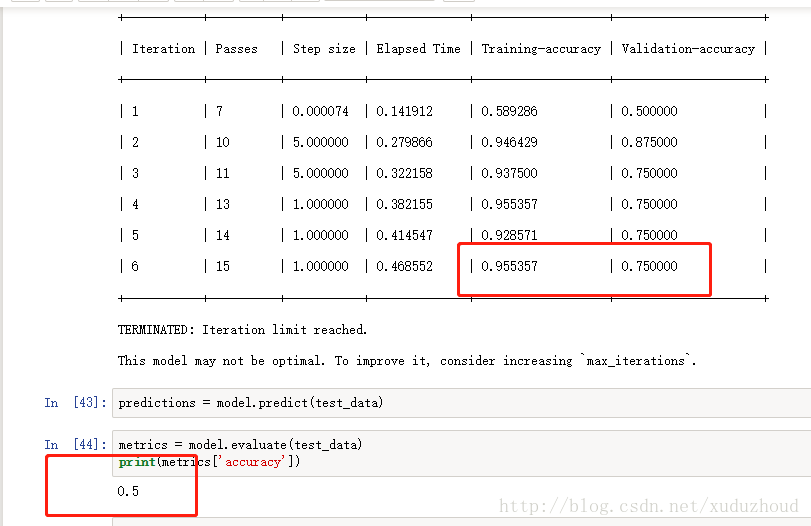
训练精度0.955 验证精度才0.75 正确率才0.5。好吧,看来是学习得太少,得上三年高考五年模拟版,将暹罗和英短的图片都增加到100张。在看结果。
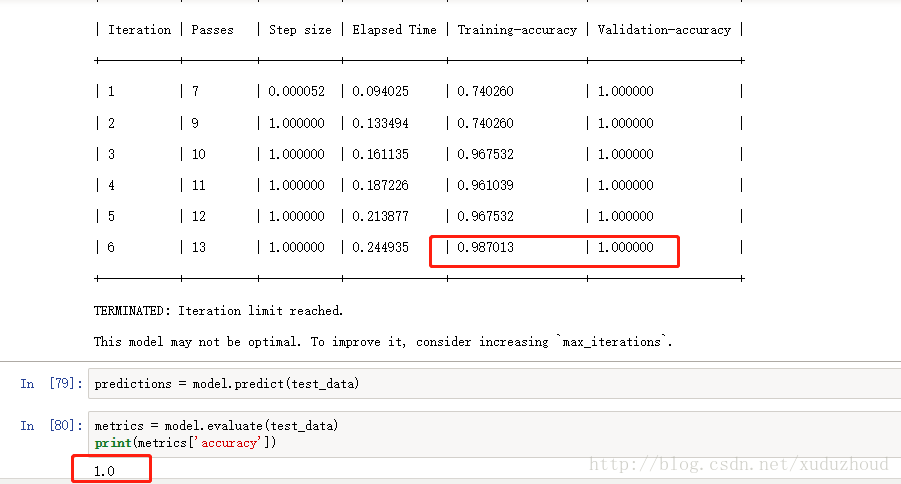
这次训练精度就达到0.987了,验证精度1.0,正确率1.0 牛逼了。
看下turicreate识别的结果:
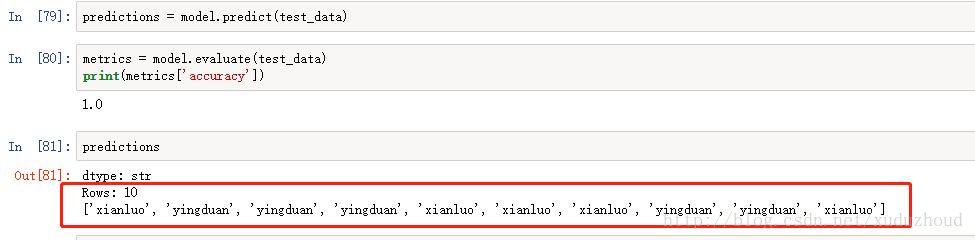
我们实际图片上猫是:(红色为真实的猫的类型-在代码里根据图片名称标记的,绿色为识别出来的猫的类型)
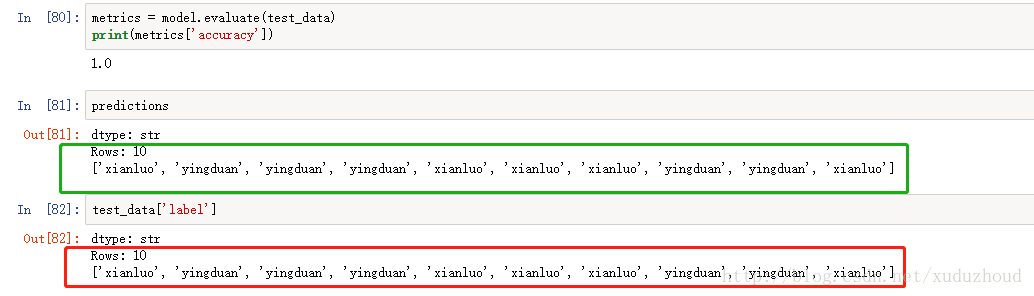
可以看到两者是一致的。牛逼了训练数据才两百张图片,就可以达到这种效果。