

 English
EnglishELK实时日志分析平台的搭建部署及使用
一、 ELK初步接触
1.1 为什么要用ELK
日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
通常,日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样是不是感觉很繁琐和效率低下。当务之急我们使用集中化的日志管理,例如:开源的syslog,将所有服务器上的日志收集汇总。
集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
• Elasticsearch是个开源分布式搜索引擎,它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
• Logstash是一个完全开源的工具,他可以对你的日志进行收集、过滤,并将其存储供以后使用(如,搜索)。
• Kibana 也是一个开源和免费的工具,它Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助您汇总、分析和搜索重要数据日志。
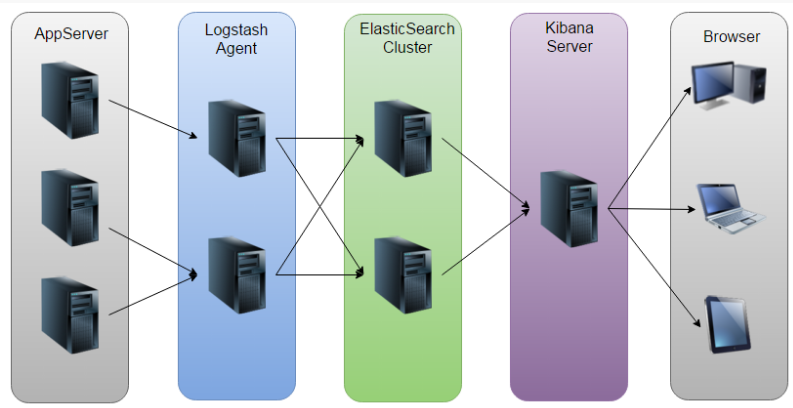
以上是ELK架构图
Elasticsearch下载地址:https://www.elastic.co/downloads/elasticsearch(目前最新版本:5.4.3)
Logstash下载地址:https://www.elastic.co/downloads/logstash(目前最新版本:5.4.3)
Kibana下载地址:https://www.elastic.co/downloads/kibana(目前最新版本:5.4.3)
1.2 Java 8
elasticsearch 推荐使用java8,所以先安装好java8。
1.3 Elasticsearch
elasticsearch的安全机制不允许用root用户启动,故新建用户elk:elk。
以elk用户启动elasticsearch:
1 2 | $ su - elk $ elasticsearch-5.4.3/bin/elasticsearch & |
安装结束后:curl localhost:9200 返回如下内容表示安装成功。
1 2 3 4 5 6 7 8 9 10 11 12 13 | { "name" : "aQgGH94", "cluster_name" : "elasticsearch", "cluster_uuid" : "BjFsa-KxQdSnP58Enrr6NA", "version" : { "number" : "5.4.3", "build_hash" : "eed30a8", "build_date" : "2017-06-22T00:34:03.743Z", "build_snapshot" : false, "lucene_version" : "6.5.1" }, "tagline" : "You Know, for Search" } |
安装过程中可能会出现的问题及解决:http://blog.csdn.net/leehbing/article/details/74627134
1.4 Kibana
修改配置文件kibana-5.4.3-linux-x86_64/config/kibana.yml:
# The Elasticsearch instance to use for all your queries.
elasticsearch.url: “http://localhost:9200”
执行:
1 2 | $ su – elk
$ ./kibana |
1.5 Nginx
前面kibana只能采用localhost访问,这里利用反向代理使其他机器可以访问,本文利用nginx来达到这一目的。
修改配置文件nginx/nginx.conf:
将默认的server{}这一段去掉,添加:include conf.d/*.conf;
1 | $ vi nginx/conf.d/kibana.conf |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | server { listen 80; server_name bogon; #机器的hostname # auth_basic "Restricted Access"; # auth_basic_user_file /etc/nginx/htpasswd.users; location / { proxy_pass http://localhost:5601; #范文kibana的地址 proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection 'upgrade'; proxy_set_header Host $host; proxy_cache_bypass $http_upgrade; } } |
1 | $ ./nginx/sbin/nginx #启动nginx |
1.6 Logstash
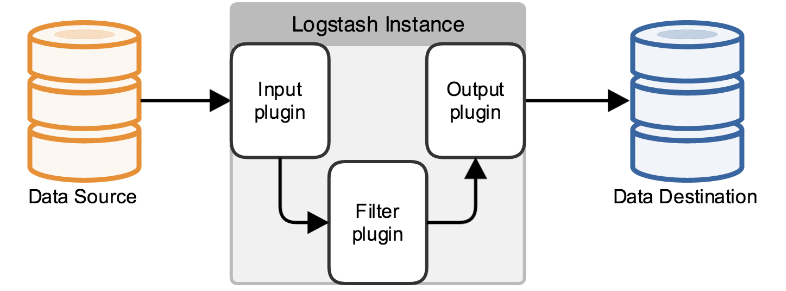
其实它就是一个收集器而已,我们需要为它指定Input和Output(当然Input和Output可以为多个)。
新建索引配置文件
1 2 3 | $ cd logstash-5.4.3/bin $ mkdir conf $ vi conf/logstash-indexer.conf |
1 2 3 4 5 6 7 8 9 10 | input { file { path => ["/var/opt/log/a.log","/var/opt/log/b.log"] } } output { elasticsearch { hosts => ["localhost:9200"] } stdout { codec => rubydebug } } |
上面几个步骤的意思就是创建一个名为logstash-indexer.conf的配置文件,input{file{…}}部分指定的是日志文件的位置(可以多个文件),一般来说就是应用程序log4j输出的日志文件。output部分则是表示将日志文件的内容保存到elasticsearch,这里hosts对应的是一个数组,可以设置多个elasticsearch主机,相当于一份日志文件的内容,可以保存到多个elasticsearch中。stdout,则表示终端的标准输出,方便部署时验证是否正常运行,验证通过后,可以去掉。
1 | $ ./logstash -f conf/logstash-indexer.conf #启动logstash |
稍等片刻,如果看到Logstash startup completed,则表示启动成功。然后另开一个终端窗口,随便找个文本编辑工具(比如:vi),向/var/opt/log/a.log里写点东西,比如:hello world之类,然后保存。观察logstash的终端运行窗口,是否有东西输出,如果有以下类似输出:
1 2 3 4 5 6 7 | { "path" => "/var/opt/log/a.log", "@timestamp" => 2017-07-09T03:17:28.001Z, "@version" => "1", "host" => "bogon", "message" => "hello word" } |
在浏览器中输入http://192.168.1.139,即会跳转至kibana页面,首次运行,会提示创建index,直接点击Create按钮即可。
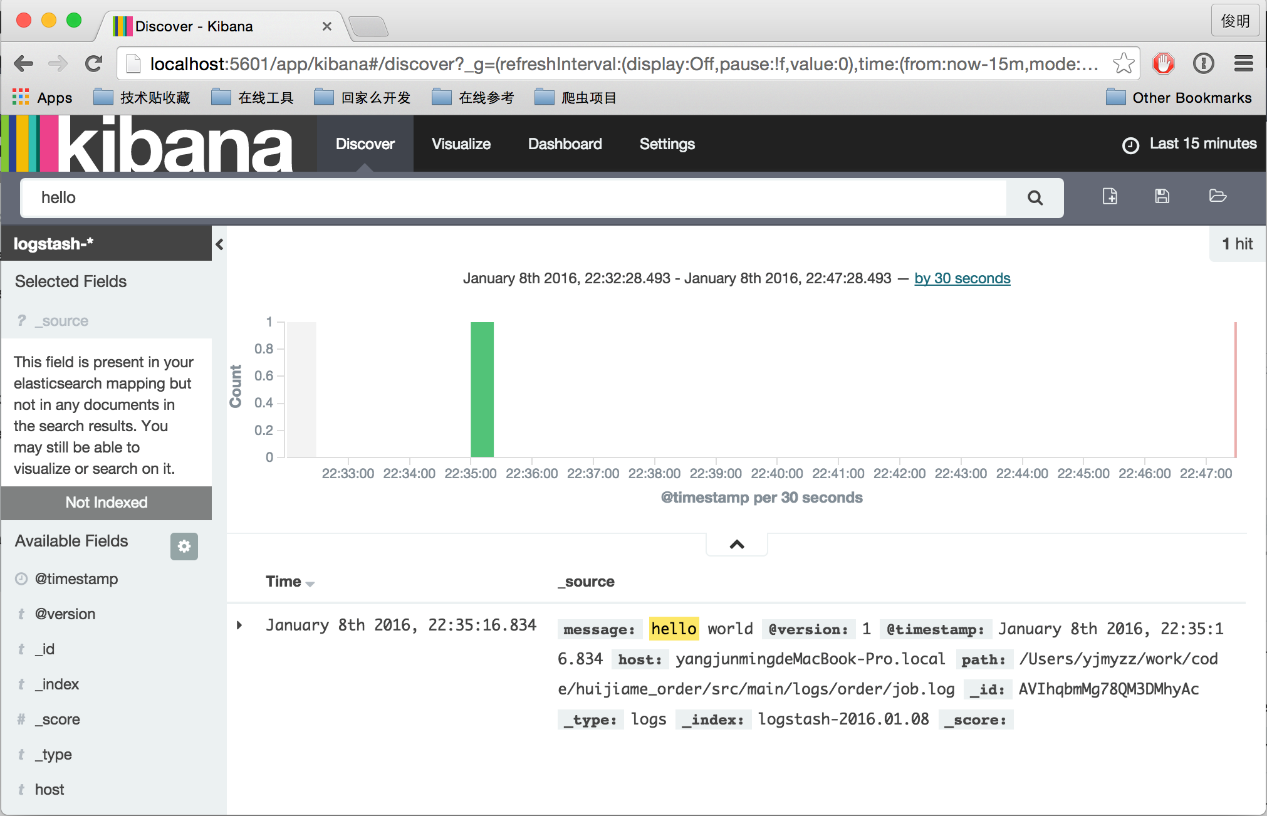
二、 应用场景示例
2.1 收集多个服务器的日志
在客户服务器安装Filebeat,将日志发送给logstash。

2.1.1 生成SSL认证
因为要使用Filebeat将日志从客户端发送到ELK,所以需要创建SSL认证和秘钥对。Filebeat会使用该认证来识别ELK。有两种方法来生成SSL认证。如果已经有DNS设置,即可以使客户端识别ELK服务端的IP地址,使用第二种方法,否则使用第一种方法。
第一种方法:IP地址
如果没有DNS设置(DNS的设置可以让产生日志的客户端服务器来识别ELK服务器的IP地址),必须将ELK服务器的IP地址添加到SSL认证的subjectAltName(SAN)域中。
$ vi /etc/pki/tls/openssl.cnf #编辑OpenSSl的配置文件
找到[ v3_ca ]段,在其下加入subjectAltName = IP: ELK_server_private_ip(ELK_server_private_ip为ELK的IP地址)
利用以下命令来生成SSL认证以及私钥
1 2 | $ cd /etc/pki/tls #在/etc/pki/tls/目录下 $ openssl req -config /etc/pki/tls/openssl.cnf -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt |
第二种方法:FQDN (DNS)
直接利用以下命令来生成SSL认证以及私钥(在/etc/pki/tls/目录下)(ELK_server_fqdn:ELK服务器的FQDN)
1 2 | $ cd /etc/pki/tls $ openssl req -subj '/CN=ELK_server_fqdn/' -x509 -days 3650 -batch -nodes -newkey rsa:2048 -keyout private/logstash-forwarder.key -out certs/logstash-forwarder.crt |
2.1.2 配置logstash
Logstash的配置文件采用json的格式,配置文件包括三个部分:inputs,filters,outputs。
1 | $ vi bin/conf/02-beats-input.conf |
1 2 3 4 5 6 7 8 | input { beats { port => 5044 ssl => true ssl_certificate => "/etc/pki/tls/certs/logstash-forwarder.crt" ssl_key => "/etc/pki/tls/private/logstash-forwarder.key" } } |
描述一个beats输入,监听tcp端口5044,并且会利用前面创建的ssl认证即秘钥
1 | $ vi bin/conf/10-syslog-filter.conf |
1 2 3 4 5 6 7 8 9 10 11 12 13 | filter { if [type] == "syslog" { grok { match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" } add_field => [ "received_at", "%{@timestamp}" ] add_field => [ "received_from", "%{host}" ] } syslog_pri { } date { match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ] } } } |
对syslog类型(Filebeat进行标记)的日志进行过滤,并利用grok将输入的syslog日志解析
以使之结构化并且利于查询。
1 | $ vi bin/conf/30-elasticsearch-output.conf |
1 2 3 4 5 6 7 8 9 | output { elasticsearch { hosts => ["localhost:9200"] sniffing => true manage_template => false index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}" document_type => "%{[@metadata][type]}" } } |
将beats数据存储到elasticsearch(localhost:9200)并设置了index和type
如果要为其他使用Filebeats输入的应用添加filter,请确保将这些文件正确命名,以使该文件的顺序位于input和output文件之间(比如在02-和30-之间)
2.1.3 加载kibana仪表盘
elastic提供了一些kibana仪表盘和Beats索引模式的样例,虽然本文不会使用这些仪表盘,但是还是会加载这些仪表盘,因为我们可以使用它们包含的Filebeat索引模式。
下载仪表盘样例文件:
1 2 3 4 5 | $ curl -L -O https://download.elastic.co/beats/dashboards/beats-dashboards-1.1.0.zip $ yum -y install unzip #安装unzip $ unzip beats-dashboards-*.zip $ cd beats-dashboards-* $./load.sh #加载仪表盘样例 |
刚刚加载了如下索引模式:
1 2 3 4 | [packetbeat-]YYYY.MM.DD [topbeat-]YYYY.MM.DD [filebeat-]YYYY.MM.DD [winlogbeat-]YYYY.MM.DD |
当使用kibana的时候,将选择Filebeat索引模式作为默认。
2.1.4 加载Filebeat索引模板
因为打算使用FIlebeats来将日志送至elasticsearch,应该加载Filebeat索引模板。这个索引模板将会配置elasticsearch以机智的方式来分析送进来的Filebeat字段。
1 2 | $ curl -O https://gist.githubusercontent.com/thisismitch/3429023e8438cc25b86c/raw/d8c479e2a1adcea8b1fe86570e42abab0f10f364/filebeat-index-template.json #下载Filebeat索引模板 $ curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@filebeat-index-template.json #加载此模板 |
现在ELK服务器已经准备好接受Filebeat数据。
2.1.5 在Client主机上安装FileBeat软件包
复制SSL认证
在ELK服务器上,拷贝之前创建的SSL证书到客户端服务器上。
1 | $ scp /etc/pki/tls/certs/logstash-forwarder.crt user@client_server_private_address:/tmp |
在客户机上:
1 2 | $ mkdir -p /etc/pki/tls/certs $ cp /tmp/logstash-forwarder.crt /etc/pki/tls/certs/ |
安装Filebeat包
准备好filebeat-5.5.0-linux-x86_64.tar.gz
配置Filebeat
配置Filebeat来连接到Logstash
在客户服务器上:
1 | $ vi filebeat/filebeat.yml |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | filebeat: prospectors: #定义了哪些日志文件可以被传送给Logstash,并且该如何处理它们 - #表示开始定义prospector paths: - /var/log/secure #表示传送secure和messages日志 - /var/log/messages # - /var/log/*.log input_type: log document_type: syslog #传送的日志类型为syslog,其也是Logstash过滤器配置的 registry_file: /var/lib/filebeat/registry output: logstash: hosts: ["elk_server_private_ip:5044"] #ELK服务器的IP,发送至Loastash bulk_max_size: 1024 tls: # List of root certificates for HTTPS server verifications certificate_authorities: ["/etc/pki/tls/certs/logstash-forwarder.crt"] shipper: logging: files: rotateeverybytes: 10485760 # = 10MB |
注意,Filebeat的配置文件是YAML格式的,所以空格数是很重要的。
现在Filebeat就会发送客户服务器上的syslog messages and secure文件到ELK服务器!其他的客户端服务器一样配置。
2.2 kibana案例数据
这里直接将数据导入elasticsearch,即假设数据源的数据已经存储到elasticsearch中,然后利用kibana来对数据进行可视化。
导入以下三种数据:
1. 莎士比亚的所有著作,合适地解析成了各个字段:shakespeare.json。
2. 随机生成的虚构账号数据:accounts.json
3. 随机生成的日志文件:logs.jsonl
shakespear.json的数据格式如下:
1 2 3 4 5 6 7 8 | { "line_id": INT, "play_name": "String", "speech_number": INT, "line_number": "String", "speaker": "String", "text_entry": "String", } |
accounts.json的数据格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 | { "account_number": INT, "balance": INT, "firstname": "String", "lastname": "String", "age": INT, "gender": "M or F", "address": "String", "employer": "String", "email": "String", "city": "String", "state": "String" } |
logs.jsonl的主要数据格式如下:
1 2 3 4 5 | { "memory": INT, "geo.coordinates": "geo_point" "@timestamp": "date" } |
在kibana界面建立三个索引模式,分别对应刚刚导入es的索引:
1 2 3 | logstash-2015.05* -> logs.jsonl bank* -> account.json shakes* -> shakespear |
然后利用kibana的visualize功能可定制如下图表展示:
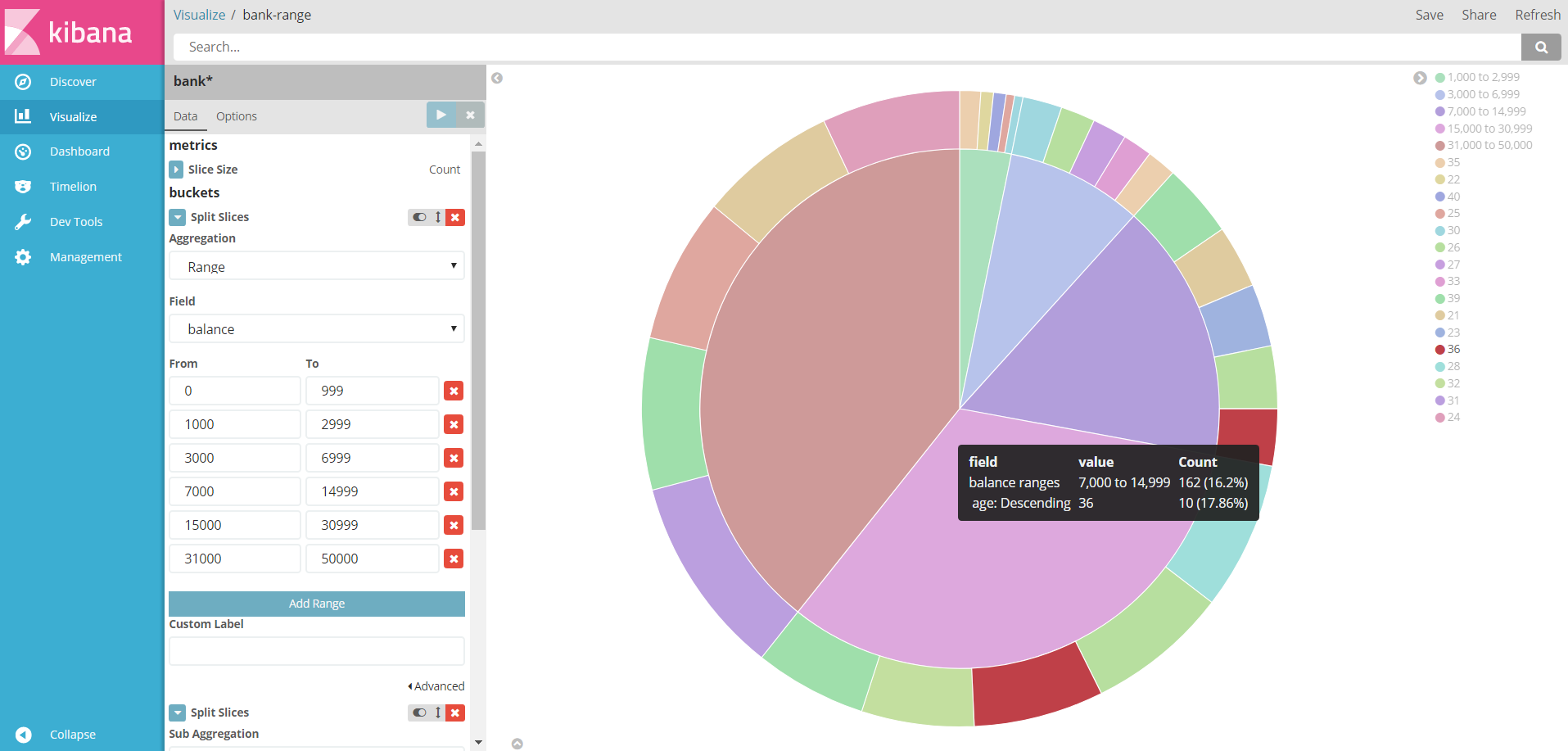
图 账户落在不同薪水范围的比率,最外圈表示按薪水所有者的年龄拆分
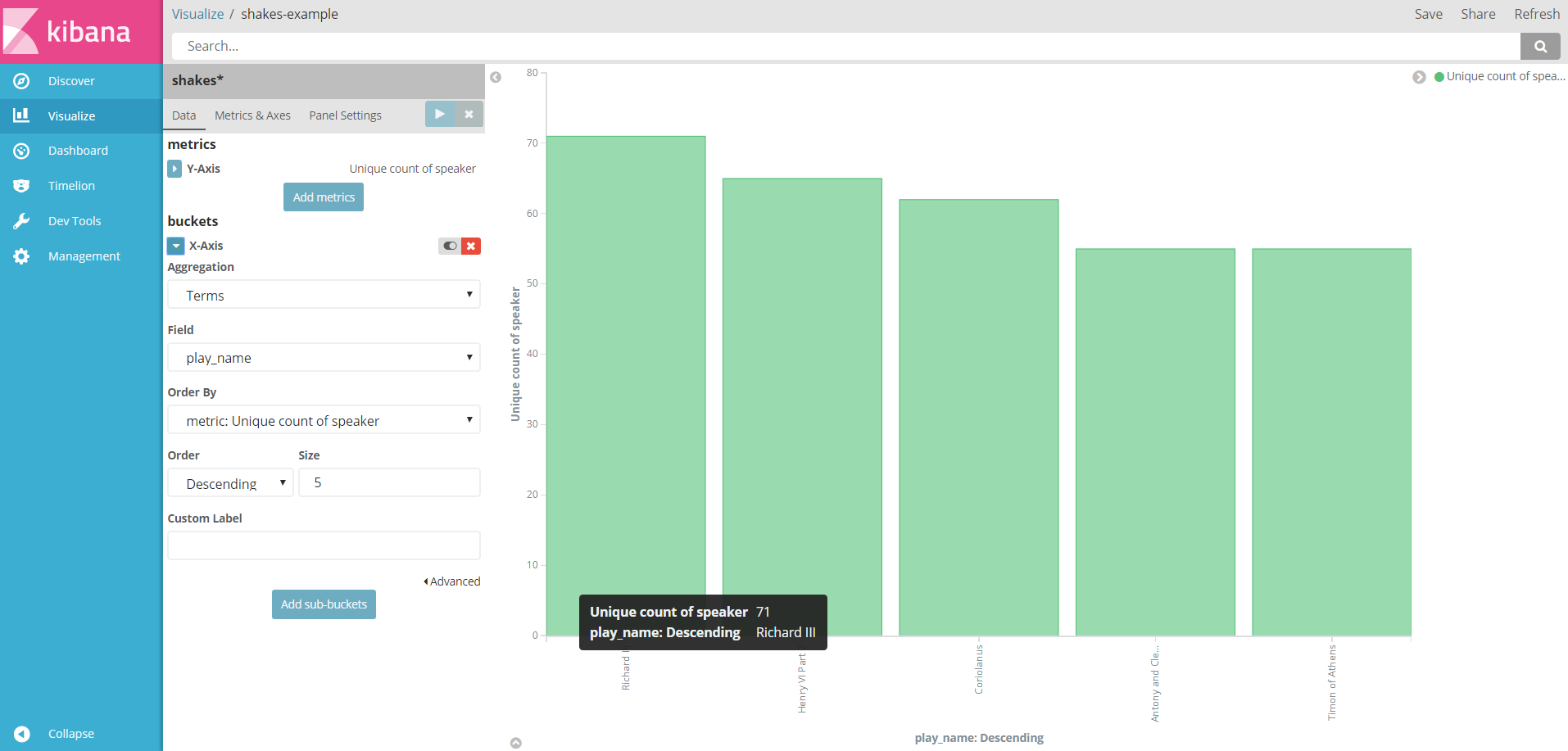
图每个剧台前幕后的数量
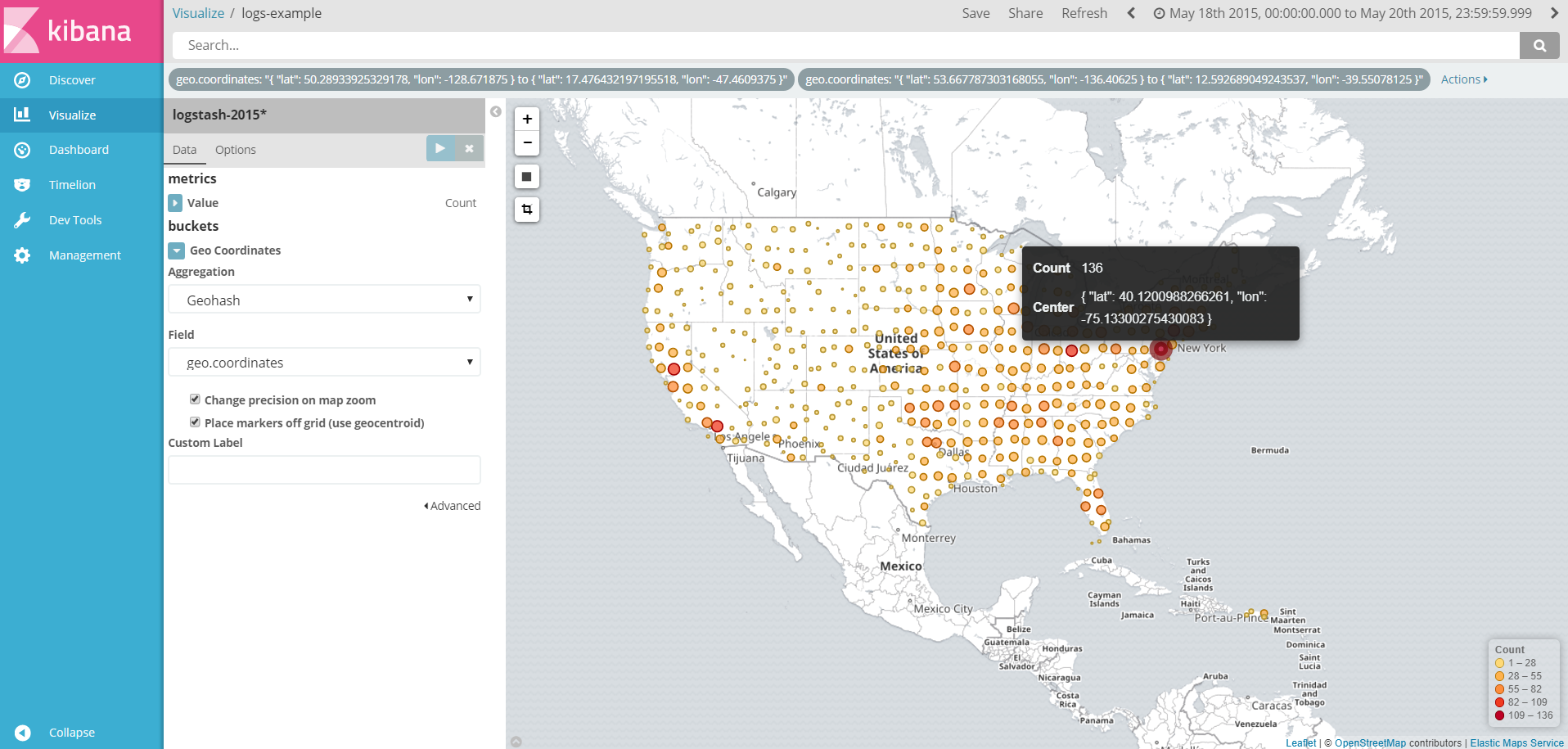
图可视化一些地理数据